Allgemeines
Jetzt kommt die schwierigste Methode von allen, das Löschen von Knoten des Baumes. Aber wir werden jetzt ganz systematisch vorgehen und dadurch auch dieses komplizierte Problem in den Griff bekommen.
Zunächst einmal überlegen wir uns den groben Algorithmus. Das Löschen besteht aus zwei Schritten: im Schritt 1 muss das zu löschende Element gefunden werden, und im Schritt 2 wird das Element dann gelöscht.
Suchen des zu löschenden Elements
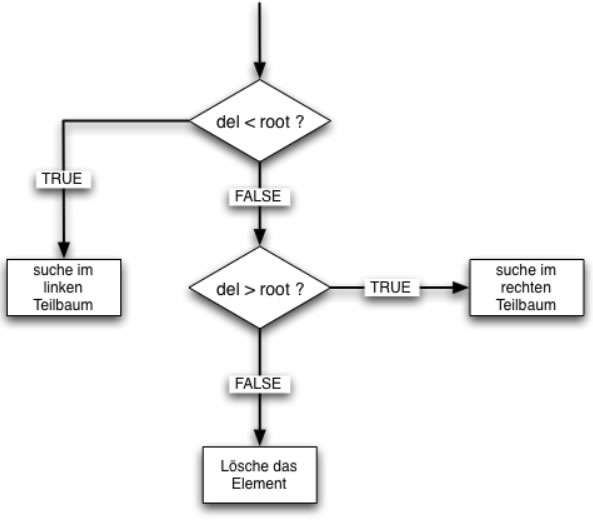
Flussdiagramm zum Finden des zu löschenden Elements
In dem obigen Flussdiagramm ist del der Wert des zu löschenden Elementes und root der Wert der Wurzel. Man erkennt leicht, dass es sich hierbei um einen rekursiven Algorithmus handelt.
Löschen eines Elementes
Wir unterscheiden hier drei Fälle:
- Der zu löschende Knoten ist ein Blatt, hat also weder einen linken noch einen rechten Nachfolger.
- Der zu löschende Knoten ist ein innerer Knoten mit nur einem Nachfolger.
- Der zu löschende Knoten ist ein innerer Knoten mit zwei Nachfolgern.
Der Fall 1 ist der am einfachsten zu implementierende Algorithmus. Beschäftigen wir uns zunächst damit, wie man ein Blatt aus einem Baum löscht.
Fall 1 - Löschen eines Blattes
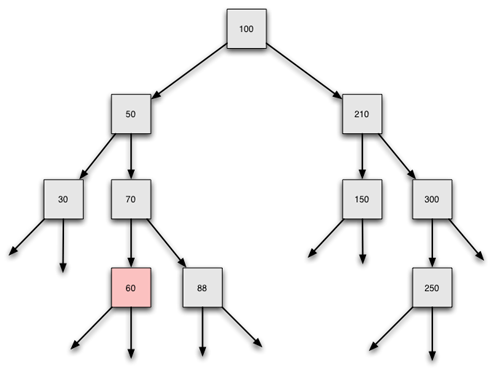
Der Baum vor dem Löschen des Elementes 60
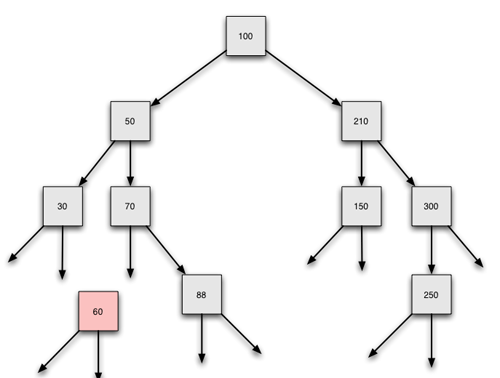
Der Baum nach dem Löschen des Elementes 60
Ein Blatt wie die 60 kann ganz einfach gelöscht werden, indem der Zeiger, der auf das Element verweist, auf null gesetzt wird. Der Knoten mit der 60 existiert zwar noch für kurze Zeit im Arbeitsspeicher, ist aber nicht mehr in den Binärbaum integriert und kann daher nicht "wiedergefunden" werden. Bei der inorder-Ausgabe, beim rekursiven Einfügen, bei der Suche und bei anderen Operationen wird die 60 nicht mehr berücksichtigt. Es ist so, als ob der Knoten gar nicht mehr da wäre. Außerdem hat Java einen eingebauten "garbage collector", also einen "Mülleinsammler", der regelmäßig solche verwaisten Datenfragmente wie den Knoten mit der 60 sowie die left- und right-Zeiger der 60 aus dem Speicher löscht.
Das Löschen des Knotens geht im Prinzip ganz einfach; der left-Zeiger der 70 muss auf null gesetzt werden. Das Problem hierbei ist, den Vorgängerknoten erstmal zu finden. Damit werden wir uns aber erst später beschäftigen. Wir merken uns einfach:
Ein Blatt wird gelöscht, indem der left- oder right-Zeiger des Vorgängerknotens auf null gesetzt wird. Den Rest erledigt der garbabe collector von Java.
Fall 2 - Löschen eines Knotens mit genau einem Nachfolger
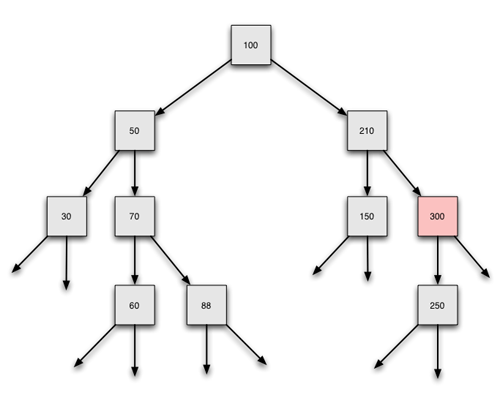
Der Baum vor dem Löschen des Elementes 300
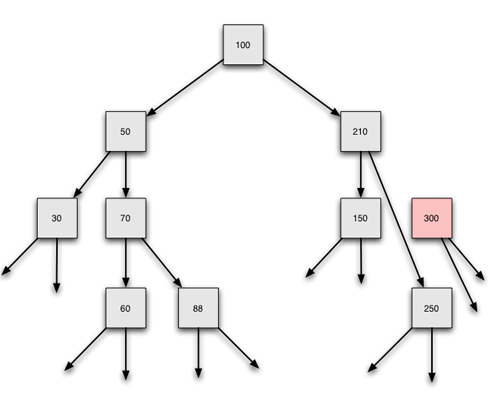
Der Baum nach dem Löschen des Elementes 300
Hier reicht es nicht, den left- oder right-Zeiger des Vorgängerknotens auf null zu setzen. Dann wäre nämlich nicht nur der zu löschende Knoten 300 verschwunden, sondern auch der linke Nachfolger der 300, nämlich die 250.
Die Lösung des Problems: Der right-Zeiger der 210 wird nicht auf null gesetzt, sondern auf den einzigen vorhandenen Nachfolger der 300, hier also auf die 250.
Angenommen, die 250 hätte selbst noch einen linken und einen rechten Nachfolger, beispielsweise die 250 und die 260. Würde sich dann etwas an diesem Verfahren ändern? Nein, der right-Zeiger der 210 würde auf die 250 gesetzt, und damit wäre nicht nur die 250 "gerettet", sondern auch sämtliche Nachfolger der 250.
In dem unteren der beiden Bilder sieht man auch, dass der left-Zeiger der 300 auf null gesetzt wurde. An sich ist das nicht notwendig, der garbage-collector würde die verwaiste 300 dennoch löschen. Aber schön sieht das nicht aus, wenn die 250 zwei Vorgänger hat, den alten 300er-Knoten und den neuen 210er Knoten. Aus ästhetischen Gründen ist es besser, die Nachfolger des zu löschenden Knoten auf null zu setzen. Oder falls es mal eine Java-Version geben sollte, in der der garbage-collector sich daran stört, dass das verwaiste Element noch mit anderen Daten verbunden ist.
Ein Knoten mit genau einem Nachfolger wird gelöscht, indem der left- oder right-Zeiger des Vorgängerknotens auf den einzigen Nachfolger des zu löschenden Knoten gesetzt wird.
Fall 3 - Löschen eines Knotens mit genau zwei Nachfolgern
Man sollte jetzt ja denken, dass das Löschen eines Knotens mit zwei Nachfolgern noch komplizierter ist als wenn man einen Knoten mit nur einem Nachfolger löscht. Aber das Gegenteil ist der Fall. Schauen Sie sich folgenden umgangssprachlich formulierten Algorithmus an:
Ersetze den Inhalt des zu löschenden Knotens durch den größten Wert des linken Teilbaums oder alternativ durch den kleinsten Wert des rechten Teilbaumes. Lösche anschließend den auf diese Weise duplizierten Knoten mit der bei Fall 1 oder 2 beschriebenen Methode.
Das wollen wir uns auch wieder an einem Beispiel klarmachen.
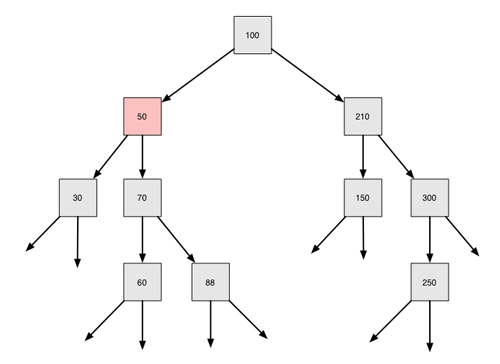
Der Baum vor dem Löschen der 50
Die 50 soll gelöscht werden. Der rechte Teilbaum besteht aus der 70 mit den beiden Nachfolgern 60 und 88. Wir suchen jetzt das kleinste Element des rechten Teilbaums...
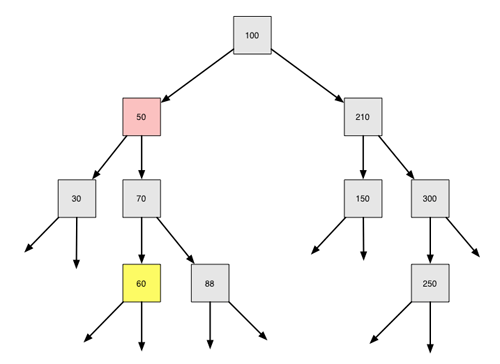
Das kleinste Element des rechten Teilbaums wurde gefunden
und finden die 60. Dieser Wert wird jetzt in das zu löschende Element hineinkopiert. Der Wert 50 wird also durch den Wert 60 ersetzt / überschrieben:
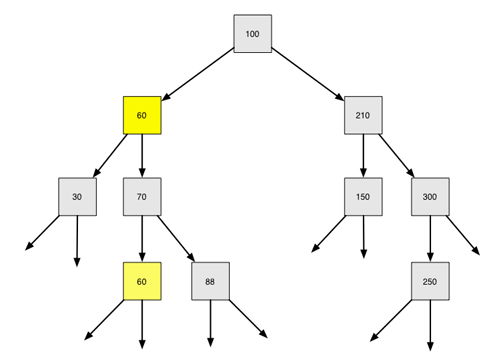
Die 50 wird mit der 60 überschrieben
Der Wert 60 existiert jetzt zweimal im Baum. Das ist aber nicht schlimmen, denn im letzten Schritt wird die "alte" 60 gelöscht:
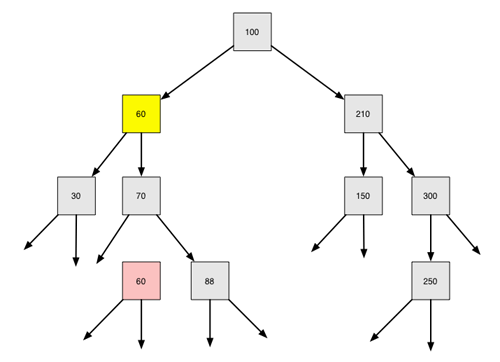
Der
Der Knoten mit der 60 ist ein Blatt, also kann zum Löschen der 60 die Methode 1 angewandt werden.
Ein Knoten mit zwei Nachfolgern wird gelöscht, indem der Wert des Knotens mit dem größten Wert des linken Nachfolgers oder dem kleinsten Wert des rechten Nachfolgers überschrieben wird. Anschließend wird der duplizierte Knoten mit Methode 1 oder 2 gelöscht.
Ein (nahezu) lauffähiger Quelltext
So weit ich weiß, verlangen die meisten Informatik-Richtlinien noch nicht einmal, dass die Schüler eine rekursive insert-Methode für einen binären Suchbaum selbst implementieren sollen, geschweige denn eine rekursive delete-Methode. Darum wird hier auch keine entsprechende Aufgabe gestellt, sondern wir schauen uns mal den Quelltext einer einigermaßen lauffähigen delete-Methode an und versuchen, diesen Algorithmus zu verstehen. Mit den weiter oben besprochenen drei Fällen sollte das ja eigentlich kein Problem mehr sein.
Die Implementation ist sehr lang geworden. Im Internet oder in der Fachliteratur findet man wesentlich kürzere Quelltexte. Das der Quelltext so lang ist, hat aber didaktisch-methodische Gründe. Ich wollte unbedingt die drei Fälle, die wir oben besprochen habe, im Quelltext abbilden. Außerdem sollte das Aufsuchen des zu löschenden Elementes in eine eigene Methode ausgelagert werden, damit auch dieses Vorgehen klarer wird.
Das Finden des zu löschenden Knoten
private class twoPointers
{
Element toDelete, prev;
public twoPointers(Element d, Element p)
{
toDelete = d;
prev = p;
}
}
Diese kleine Java-Klasse ist sehr hilfreich bei der Implementierung der delete-Methode. Sie erinnern sich; bei der Besprechung der Lösch-Routinen war oft von zwei Hilfszeigern die Rede. Der Zeiger toDelete verweist auf den zu löschenden Knoten, der Zeiger prev verweist auf den Vorgänger dieses Knotens.
private twoPointers findElement(int v)
{
twoPointers help = new twoPointers(root,null);
while ((help.toDelete != null) && (help.toDelete.value != v))
{
help.prev = help.toDelete;
if (v < help.toDelete.value) help.toDelete = help.toDelete.left; else
if (v > help.toDelete.value) help.toDelete = help.toDelete.right;
}
return help;
}
Die Methode findElement sucht nun das zu löschende Element und liefert nicht nur einen Zeiger auf dieses Element zurück, sondern gleichzeitig auch einen Zeiger auf den Vorgänger dieses Elementes. Da eine sondierende Methode immer nur einen Wert zurückliefern kann, hätten wir jetzt ein kleines Problem, da ja zwei Werte zurückgeliefert werden sollen. Mit Hilfe der Klasse twoPointers ist das jetzt aber kein Problem.
Das eigentliche Löschen
Kommen wir nun zum eigentlichen Löschvorgang.
Vorbereitung
Hier zunächst die "Mantelmethode" für den gewöhnlichen User der Klasse:
public void delete(int v)
{
twoPointers help = findElement(v);
if (help.toDelete == null) return;
if (isLeaf(help.toDelete)) deleteLeaf(help); else
if (isNode1(help.toDelete)) deleteNode1(help); else
if (isNode2(help.toDelete)) deleteNode2(help);
}
Der User der Klasse sieht nur die öffentliche delete-Methode, die nur einen Parameter hat, nämlich den Wert des Elementes, das gelöscht werden soll.
Zunächst wird ein Zeigerpaar erzeugt und auf den zu löschenden Knoten und seinen Vorgänger gesetzt. Falls der gesuchte Wert nicht im Baum vorhanden ist - was ja vorkommen kann - wird die delete-Methode beendet.
Falls die Methode nicht beendet wurde, werden die drei möglichen Fälle überprüft und die entsprechende Subroutine ausgeführt. Wenn es sich bei dem zu löschenden Knoten um ein Blatt handelt, was mittels der sondierenden Methode isLeaf festgestellt wird, wird die Subroutine deleteLeaf aufgerufen. Handelt es sich um einen Knoten mit genau einem Nachfolger wird deleteNode1 aufgerufen, und wenn der Knoten genau zwei Nachfolger hat, wird entsprechend deleteNode2 ausgeführt.
Die eigentlichen Lösch-Routinen
Löschen eines Blattes
private void deleteLeaf(twoPointers pp)
{
if (pp.toDelete == pp.prev.left)
pp.prev.left = null;
else
pp.prev.right = null;
}
Hier muss nur entschieden werden, ob der zu löschende Knoten der linke oder der rechte Nachfolger des Vorgängerknotens ist. Im ersten Fall wird der left-Zeiger des Vorgängers auf null gesetzt, im zweiten Fall der right-Zeiger.
Löschen eines Knotens mit einem Nachfolger
private void deleteNode1(twoPointers pp)
{
if (pp.toDelete == pp.prev.right)
{
if (pp.toDelete.left != null) pp.prev.right = pp.toDelete.left; else
if (pp.toDelete.right != null) pp.prev.right = pp.toDelete.right;
}
else if (pp.toDelete == pp.prev.left)
{
if (pp.toDelete.left != null) pp.prev.left = pp.toDelete.left; else
if (pp.toDelete.right != null) pp.prev.left = pp.toDelete.right;
}
}
Hier sind insgesamt vier Fälle zu unterscheiden, wie bereits weiter oben beschrieben wurde. Erinnern wir uns an den Merktext:
Ein Knoten mit genau einem Nachfolger wird gelöscht, indem der left- oder right-Zeiger des Vorgängerknotens auf den einzigen Nachfolger des zu löschenden Knoten gesetzt wird.
Es muss also erstens entschieden werden, ob der zu löschende Knoten der linke oder der rechte Nachfolger des Vorgängerknotens ist. Dazu dienen die beiden "äußeren" if-Abfragen, die im Quelltext rot markiert sind.
Wenn dies entschieden ist, muss ja der einzige Nachfolger des zu löschenden Knoten an den Vorgängerknoten "gehängt" werden. Dazu muss der left- bzw. right-Zeiger des Vorgängerknotens entweder auf den linken oder auf den rechten Nachfolger des zu löschenden Knoten gesetzt werden. Dazu dienen die vier "inneren" Fallunterscheidungen.
Löschen eines Knotens mit zwei Nachfolgern
private void deleteNode2(twoPointers pp)
{
Element miniprev = pp.toDelete;
Element mini = pp.toDelete.right;
while (mini.left != null)
{
miniprev = mini;
mini = mini.left;
}
pp.toDelete.value = mini.value;
twoPointers help = new twoPointers(mini,miniprev);
if (isLeaf(help.toDelete)) deleteLeaf(help); else
if (isNode1(help.toDelete)) deleteNode1(help);
}
Der erste Teil des Algorithmus mit der while-Schleife dient zum Auffinden des kleinsten Elements des rechten Teilbaums des zu löschenden Knoten. Alternativ könnte man hier auch nach dem größten Element im linken Teilbaum suchen. Hier ist aber der erste Weg gewählt worden.
Die mittlere Zeile
pp.toDelete.value = mini.value;
dient zum Überschreiben des zu löschenden Elementes mit dem Wert des gefundenen kleinsten Elementes des rechten Teilbaums.
Im letzten Teil des Quelltextes wird ein Zeigerpaar help auf das noch vorhandene kleinste Element des rechten Teilbaums sowie auf dessen Vorgänger gesetzt. Dann wird geschaut, ob das kleinste Element ein Blatt oder ein Knoten mit genau einem Nachfolger ist, und die entsprechende Löschmethode wird aufgerufen.
Testen des Löschens
Dieser hier vorgestellte Löschalgorithmus ist sehr lang und wahrscheinlich umständlich, aber der Vorteil ist, dass er schülerfreundlich ist, weil das große Problem in lauter kleine Teilprobleme zerlegt wurde, die jedes für sich recht einfach zu verstehen sind.
Wir wollen diesen Algorithmus nun testen. Dazu schreiben wir uns eine kleine Testklasse, die zunächst einen großen Baum erzeugt, zum Beispiel aus 50 Zufallszahlen, und dann in einer langen for-Schleife 1.000 Zufallszahlen erzeugt und diese wieder aus dem Baum löscht. Sollte es dabei irgend ein Problem mit "null pointer exceptions" oder ähnlichen Fehlern geben, werden wir das früher oder später schon merken...
Die Testklasse
import java.util.Random;
public class Test
{
BinTree tree;
public Test()
{
Random wuerfel = new Random();
int zahl;
tree = new BinTree();
for (int i=1; i<=50; i++)
{
zahl = wuerfel.nextInt(1000)+1;
tree.insert(zahl);
}
tree.show();
System.out.println("===== jetzt werden 1000 Zufallszahlen geloescht ========");
for (int i=1; i<=1000; i++)
{
zahl = wuerfel.nextInt(1000)+1;
tree.delete(zahl);
}
tree.show();
}
}
Testergebnis
Bei vier Durchläufen dieser Testklasse sind keine Laufzeitfehler aufgetreten. Als die Anzahl der zu löschenden Zufallszahlen einmal auf 5.000 erhöht wurde, gab es einen Laufzeitfehler in der Methode deleteNode1, und zwar in der ersten Zeile
if (pp.toDelete == pp.prev.right)
Da dieser Fehler immer dann auftritt, wenn eine sehr große Anzahl von Elementen gelöscht werden soll, liegt die Vermutung nahe, dass das Löschen in einem leeren Baum diesen Fehler verursacht. Der Fehler verschwindet, wenn man zu Beginn einer jeden Lösch-Methode folgende if-Anweisung einbaut:
if ((pp.toDelete==null) || (pp.prev==null)) return;
Besonders elegant ist dieses Vorgehen nicht, aber es scheint ein effektiver "Workaround" zu sein, um diesen lästigen Fehler zu beseitigen.