Ein Praxisbeispiel
Im Prinzip werden sowohl bei der linearen Suche wie auch bei der binären Suche die Suchbegriffe mit den gespeicherten Begriffen verglichen. Bei der linearen Suche vergleicht man den Suchbegriff mit dem ersten Element der Datenstruktur. War die Suche erfolglos, macht man mit dem nächsten Element der Datenstruktur weiter, solange, bis man entweder den Suchbegriff gefunden hat oder bis man das Ende der Datenstruktur erreicht hat.
Ähnlich erfolgt die binäre Suche, nur dass man hier nicht beim ersten Element der Datenstruktur anfängt, sondern bei dem mittleren Element und dann systematisch nach links oder rechts weitersucht. Bei beiden Suchverfahren finden aber jede Menge Vergleiche statt, bei der linearen Suche viele, bei der binären Suche deutlich weniger Vergleiche. Das Suchen in einem binären Suchbaum kann in dieser Hinsicht mit der binären Suche verglichen werden. Auch hier sind nur wenige Vergleiche notwendig, bis das Gesuchte gefunden wurde bzw. bis feststeht, dass es nicht in den Daten vorhanden ist. Aber das heißt ja nicht, dass man diese Suchen nicht noch weiter optimieren könnte. Schauen wir uns dazu mal ein Praxisbeispiel an.

Suche in einem Telefonbuch
Photo: Ulrich Helmich 2019, Lizenz: siehe Seitenende.
Wenn Sie in einem Telefonbuch nach einem Namen wie "Beier" suchen, werden Sie das Buch doch mit Sicherheit nicht genau in der Mitte aufschlagen, sondern ziemlich weit vorne. Ihr Gehirn schätzt ab, wo ungefähr im Buch die B-Einträge stehen. Wenn Sie dann eine Seite aufgeschlagen haben, schauen Sie sich die Namen auf dieser Seite ein. Fangen diese Namen mit "C" oder "D" an, dann wissen Sie, dass Sie zu weit geblättert haben. Vielleicht machen Sie nun tatsächlich eine binäre Suche, indem Sie die Seiten, die Sie in der Hand halten, halbieren und dann gucken, wo sie gelandet sind. Mit der richtigen Hälfte verfahren Sie dann ähnlich, bis Sie die korrekte Seite gefunden haben.
Auch wenn Sie vor einem Bücherregal stehen, in dem die Bücher nach den Autorennamen aufsteigend sortiert sind, werden Sie ähnlich verfahren. Wenn Sie "Tolkien" suchen, werden Sie nicht in der Mitte bei "M" beginnen, sondern schon ziemlich weit rechts schauen. Auch hier führt Ihr Gehirn unbewusst eine Art Berechnung durch, so denn wohl der ideale Einstiegspunkt für Ihre Suche sein könnte.
Indexsuche
Betrachten Sie bitte folgendes Bild:
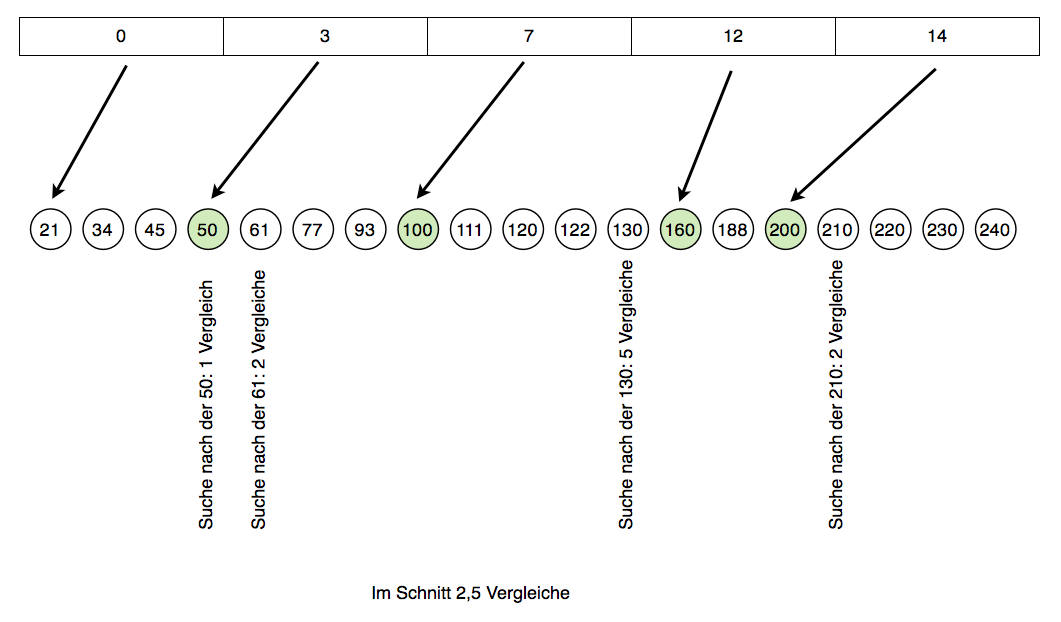
Schema zur Interpolationssuche
Autor: Ulrich Helmich 2019, Lizenz: siehe Seitenende.
Wir haben hier die gleichen Zahlen genommen wie in der Folge 12.2. Die Zahlen selbst sind in einem großen Array gespeichert, der Tausende oder sogar Hundertausende von Elementen enthalten kann; in unserem Fall sind aber nur 19 Zahlen in dem Array enthalten, damit die Abbildung 1 überhaupt noch auf diese Webseite passt.
Ganz oben im Bild sehen Sie für Kästen mit den Zahlen 0, 3, 7, 12 und 14. Was bedeuten diese Zahlen?
Die 0 ist klar. Das erste Arrayelement hat immer den Index 0. Die Zahl 3 bedeutet, dass ab dem Element mit dem Index 3 alle Zahlen größer oder gleich 50 stehen. Die Zahlen >= 100 finden sich ab Element 7, die Zahlen >= 150 ab Element 12 und die Zahlen >= 200 ab Element 14.
Diese Zahlen selbst, also 0, 3, 7, 12 und 14, können in einem neuen Array gespeichert werden, der beispielsweise den Namen "Index" haben könnte. Auf das Speichern der 0 könnte natürlich noch verzichtet werden, denn jeder Array beginnt mit Element Nr. 0.
Wir suchen jetzt mal nach der 50. Dazu besorgen wir uns die Startadresse der Zahlen >= 50 aus dem Index-Array. Die Suche in dem Hauptarray beginnt also nicht ganz vorne wie bei der linearen Suche oder in der Mitte wie bei der binären Suche oder einem binären Suchbaum, sondern an Index 3. Und wie der Zufall es will, steht dort auch schon die gesuchte Zahl 50. Wir haben also nur einen Vergleich benötigt, um die 50 zu finden.
Hier könnte man nun natürlich einwenden, dass wir ja zuvor den Startindex in dem Hilfsarray "Index" ermitteln mussten. Diese Rechenzeit müssten wir eigentlich mit berücksichtigen.
Wenn wir die 61 suchen, starten wir wieder bei Index = 3. Wir benötigen jetzt aber zwei Vergleiche, um die Zahl zu finden.
Richtig aufwendig wird die Suche nach der 130. Hier werden sage und schreibe fünf Vergleiche benötigt, um die Zahl zu finden.
Dafür finden wir die 210 bereits nach zwei Vergleichen.
Im Schnitt werden also nur 2,5 Vergleiche benötigt, um eine der vier Suchzahlen zu finden. Und dabei haben wir hier noch nicht einmal eine besonders gute Interpolationssuche verwendet. Der Hauptarray 21, 34, ..., 240 wurde in fünf Partitionen unterteilt, und die Startpunkte der fünf Partitionen wurden in dem Index-Array gespeichert. Hier gibt es mindestens zwei Optimierungsmöglichkeiten:
- Die Zahl der Partitionen könnte erhöht werden. Das würde einerseits die Suche im Hauptarray beschleunigen, andererseits aber die Suche nach dem Startindex verlangsamen, da der Index-Array größer würde.
- Das Suchverfahren innerhalb der Partitionen könnte verbessert werden. Wir haben bei unserem Beispiel eine schlichte lineare Suche verwendet. Man könnte innerhalb einer Partition aber auch binär suchen, was die Suchzeit noch einmal stark beschleunigen würde.
Dieses Verfahren, das wir jetzt einfach mal als "Indexsuche" bezeichnen wollen, eignet sich auch dann, wenn die Elemente recht unregelmäßig verteilt sind:
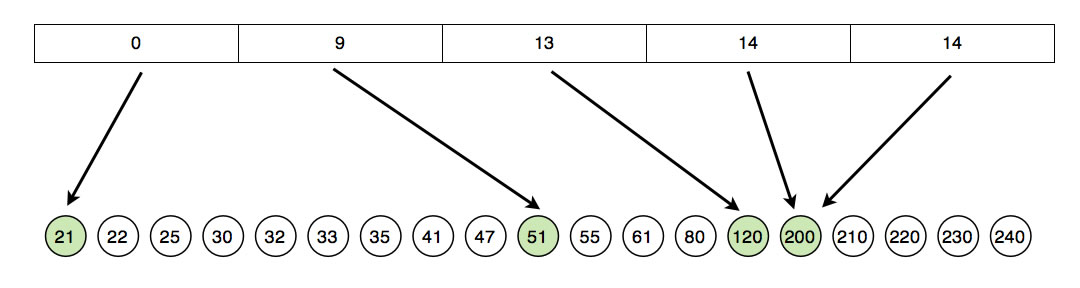
Eine ungleichmäßige Verteilung der Elemente
Autor: Ulrich Helmich 2019, Lizenz: siehe Seitenende.
Die erste Hälfte des Arrays wird von Zahlen < 50 eingenommen, in der rechten Hälfte finden sich dann Zahlen zwischen 51 und 240. Die Zahlen sind also recht ungleichmäßig verteilt.
Interpolationssuche
Wenn die Zahlen bzw. Elemente in dem Hauptarray einigermaßen gleichmäßig verteilt sind, benötigt man keinen Index-Array. Man kann versuchen, die Einstiegsposition für die Suche zu berechnen, zu interpolieren. Daher wird dieses Suchverfahren auch als Interpolationssuche bezeichnet.

50 sehr gleichmäßig verteilte Zahlen
Autor: Ulrich Helmich 2019, Lizenz: ---
Wir wollen hier nun nach vier dieser Zahlen suchen und wieder die durchschnittliche Suchzeit berechnen.
In dem Array befinden sich 50 Zahlen im Bereich zwischen 1 und 100. Wenn diese Zahlen einigermaßen gleichmäßig verteilt sind, kann man die Einstiegsposition für die Suche mit S/2 berechnen, wobei S die Suchzahl ist.
Wir wollen einmal die Zahl 50 suchen. Der Einstiegsindex ist dann 25. An der Position 25 finden wir die Zahl 52. Diese Zahl ist größer als die Suchzahl 50. Also suchen wir nach links weiter. Die erste Zahl, auf die wir stoßen, ist die 50, also die Suchzahl. Wir haben also 2 Vergleiche benötigt, um die 50 zu finden.
Die Zahl 61 ist wahrscheinlich ab Index 30 zu finden. Und dort ist sie auch, das heißt, wir haben nur 1 Vergleich benötigt, um die 61 zu finden.
Die Zahl 78 ist wahrscheinlich ab Index 39 zu finden. Dort steht die 79. Also suchen wir links weiter und finden sofort die 78. Auch hier haben wir nur 2 Vergleiche benötigt.
Auch die Zahl 94 finden wir nach 2 Vergleichen.
Die durchschnittliche Suchzeit für diese vier Zahlen liegt also unter 2,0. Eine solche Interpolationssuche ist also sehr effektiv, und man spart sich den Index-Array. Allerdings funktioniert die Interpolationssuche nur dann, wenn man die Einstiegsposition für die Suche auch tatsächlich einigermaßen zuverlässig berechnen kann. Dazu müssen die Elemente ziemlich gleichmäßig verteilt sein. Bei einer ungleichmäßigen Verteilung hilft dann aber immer noch die Indexsuche, die weiter oben erklärt wurde.
Umsetzung der Interpolationssuche
Stellen wir uns eine große sortierte Liste von Zahlen vor, vielleicht 10.000 Zahlen mit Werten zwischen 1 und 100.000. Wir gehen mal davon aus, dass diese Zahlen einigermaßen gleichmäßig verteilt sind, aber dennoch starken Zufallscharakter haben.
import java.util.Random;
public class Zufallszahlen
{
final int max = 10000;
int[] liste;
public Zufallszahlen()
{
liste = new int[max];
create();
show();
}
public void create()
{
Random wuerfel = new Random();
liste[0] = wuerfel.nextInt(10)+1;
for (int i=1; i < max; i++)
liste[i] = i*10 + wuerfel.nextInt(10)-5;
}
public void show()
{
for (int i=0; i < max; i++)
{
System.out.print(liste[i] + "\t");
if ((i+1)%10==0)
System.out.println();
}
}
}
Mit diesem kleinen Java-Quelltext kann man eine solche Liste erzeugen. Die Zahlen sind gleichmäßig verteilt und sehen zufällig aus. Hier ein Beispiel der Konsolenausgabe:
Ein Ausschnitt aus der Konsolenausgabe
Autor: Ulrich Helmich 2019, Lizenz: ---
Eine streng binäre Suche würde nun bei dem mittleren Element anfangen, das einen Wert um die 50.000 hätte. Wir wollen aber die Zahl 3.000 suchen. Wie könnten wir das sinnvoll machen?
Es ist klar, dass die 3.000 ziemlich weit vorne in dem Array steht. Aber wo genau soll die Suche beginnen?
Man könnte natürlich eine Berechnungsfunktion programmieren, die ungefähr so arbeitet: Der Array besteht aus 10.000 Zahlen im Bereich 1 bis 100.000 und die Zahlen sind mehr oder weniger gleichmäßig verteilt. Im Schnitt ist der "Abstand" zwischen zwei Zahlen 10; die Zahl 3.000 sollte also ungefähr an der Stelle 100 im Array vorkommen. Das wäre also der ideale Einstiegspunkt in die Suche.
Eine kleine Erweiterung der show-Methode zeigt uns, dass die Vermutung richtig ist: Bei einem Testdurchlauf stand die Zahl 2.999 an der Position (Index) 300. Bei einem zweiten Testdurchlauf war es die Zahl 2.997.
Da 3.000 > 2.997, müsste man mit der Suche rechts weitermachen. Bereits nach einem Suchschritt stößt man auf die Zahl 3.006 und weiß dann, dass 3.000 nicht in dem Array vorkommt.
public void suche(int suchzahl)
{
int einstieg = suchzahl/10;
for (int i=einstieg; i < max; i++)
if (liste[i]==suchzahl)
{
System.out.println(suchzahl + " an Position " + i + " gefunden!");
return;
}
else if (liste[i] > suchzahl)
{
System.out.println(suchzahl + " nicht in der Liste enthalten!");
return;
}
}
Diese Methode arbeitet nach dem oben beschriebenem Prinzip. Wenn die 3.000 gesucht wird, ist der Einstiegspunkt = 3.000/10 = 300. Dort steht die Zahl 2.998, wie der folgende Screenshot zeigt:

Ein Ausschnitt aus der Konsolenausgabe
Autor: Ulrich Helmich 2019, Lizenz: ---
Da diese Zahl kleiner ist als die Suchzahl, wird nach rechts weitergesucht. Dazu dient die for-Schleife, die jetzt alle Elemente rechts des Einstiegs mit der Suchzahl vergleicht. Wurde eine Übereinstimmung gefunden, wird die Position (der Index) der gefundenen Zahl ausgegeben, und die Methode suche terminiert. Andernfalls wird das nächste Arrayelement untersucht. Wurde eine Zahl gefunden, die größer ist als die Suchzahl, weiß der Algorithmus, dass die Suchzahl nicht in dem Array vorhanden ist und gibt eine entsprechende Meldung aus. Anschließend wird die Methode beendet.
Natürlich ist diese Beispielmethode völlig unpraktisch. Sie dient nur zur Demonstration dieser Interpolationssuche. In dem entsprechenden Wikipedia-Artikel zur Interpolationssuche findet sich eine exakte Berechnungsformel für den Einstiegspunkt der Suche. Wenn man diese Formel auf unser Beispiel von oben anwendet (Suche nach der Zahl 3.000 in einem Array der Größe 10.000 mit Zahlen zwischen 1 und 100.000), dann kommt man exakt auf den gleichen Wert, den wir weiter oben schon grob abgeschätzt haben, nämlich auf den Index 300.
Abitur Informatik NRW
Wir sind am Ende der Folge 12 angekommen. Zum Schluss schauen wir uns noch die Abiturvorgaben für das Informatik-Abitur 2020 in NRW an. Was wird hier zum Thema "Sortieren" überhaupt erwartet? In den offiziellen Vorgaben findet sich gar nichts zum Thema "Suchverfahren". Bei dem Thema "Algorithmen" steht nur "Analyse, Entwurf und Implementierung von Algorithmen" und "Struktorgramme". Bei "Daten und ihre Strukturierung" finden sich "lineare Strukturen" wie "array bis zweidimensional", "Stapel", "Schlange" und "lineare Liste" sowie "nicht-lineare Strukturen" wie "Binärbaum" und "binärer Suchbaum".
Schauen wir einmal in den Kernlehrplan, der dem Informatikunterricht zu Grunde liegt. Da steht auf Seite 22 unübersehbar: "Algorithmen zum Suchen und Sortieren". Hier die Unterpunkte:
Die Schülerinnen und Schüler
- analysieren Such- und Sortieralgorithmen und wenden sie auf Beispiele an,
- entwerfen einen weiteren Algorithmus zum Sortieren,
- beurteilen die Effizienz von Algorithmen am Beispiel von Sortierverfahren hinsichtlich Zeitaufwand und Speicherplatzbedarf.
Der erste Unterpunkt bezieht sich direkt auf Suchverfahren, und zwar im Plural. Also sollten Sie mindestens zwei verschiedene Suchverfahren kennen. Was bietet sich da besser an als die lineare bzw. sequentielle Suche und die binäre Suche. Wenn Sie dann noch die binäre Suche mit binären Suchbäumen in Verbindung setzen, haben Sie zumindest die mündliche Prüfung schon zu einem erheblichen Teil geschafft. Und wenn Sie dann auch noch auf den Unterschied zwischen Indexsuche und Interpolationssuche eingehen, wird Ihnen die Bewunderung von allen drei Mitgliedern der Prüfungskommission sicher sein.
Seitenanfang -
Sie haben das Ende der Folge 12 erreicht.
Leistungskurs Informatik weiter mit Folge 13 (Quicksort)
Grundkurs Informatik weiter mit Folge 14 (Abstrakte Datentypen)