Einführendes Beispiel
Die Datenkapselung ist ein ganz wichtiges Grundprinzip, welches die gesamte Software-Entwicklung durchzieht. Was versteht man unter diesem wichtigen Begriff?
Im Grunde werden hier die beiden Prinzipien der algorithmischen Abstraktion und der Datenabstraktion auf Objekte angewandt.
Stellen Sie sich vor, Sie wollen eine Software entwickeln, mit der Sie Bruchrechnung simulieren wollen. Als erstes spezifizieren Sie, welche Methoden bzw. Operationen die Software beherrschen soll.
Beispiel:
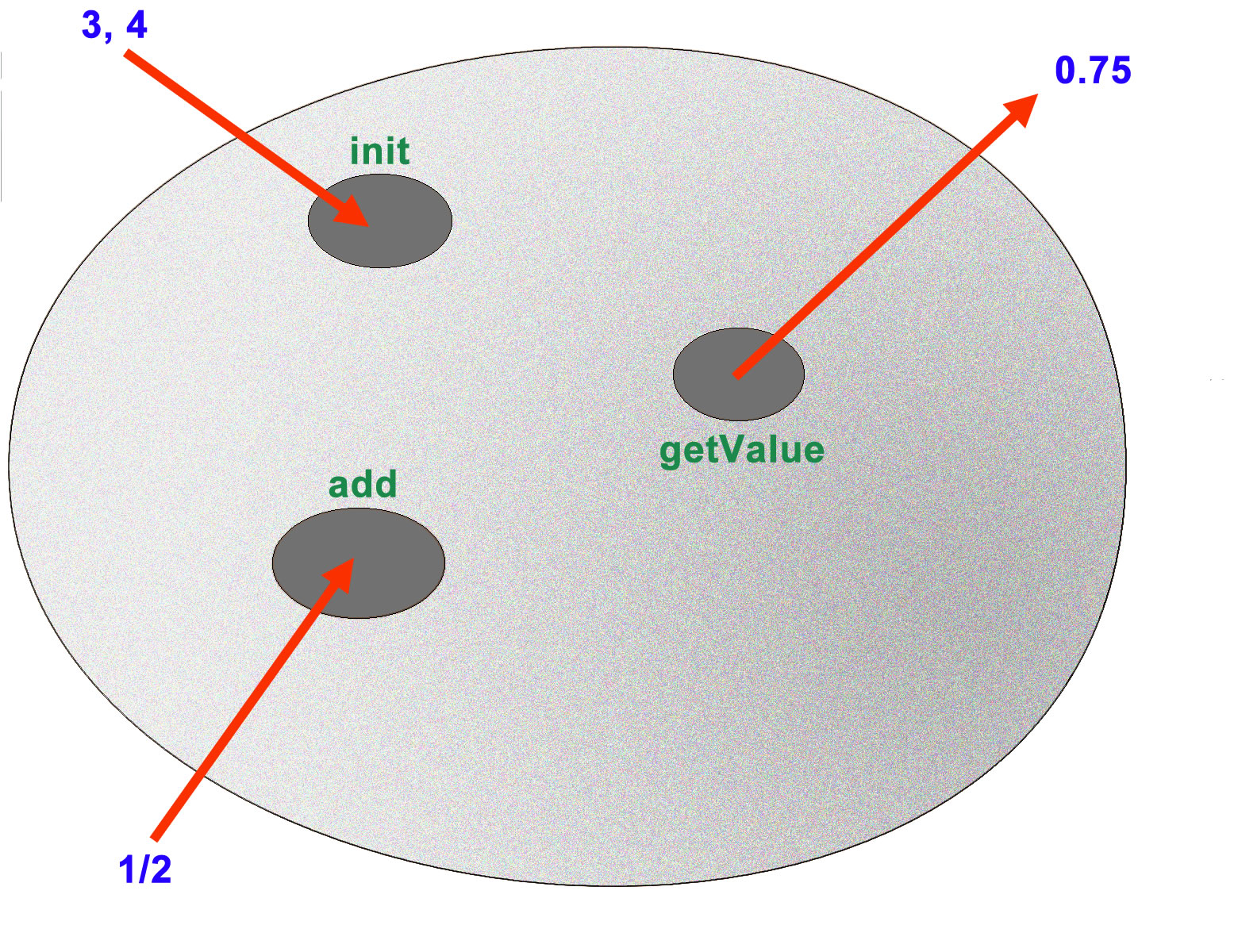
Eine Operation init(z,n) erzeugt einen neuen Bruch, dabei sind z und n die Werte für den Zähler und den Nenner.
Eine Operation getValue() liefert den rechnerischen Wert dieses Bruchs, also beispielsweise 0.75 wenn der Zähler den Wert 3 und der Nenner den Wert 4 hat.
Eine Operation add(b) addiert den Bruch b zu dem erzeugten Bruch. Wird zum Bruch 3/4 der Bruch 1/2 addiert, so ergibt sich der Bruch 5/4.
Weitere Operationen werden auf ähnliche Weise spezifiziert, aber darauf soll jetzt aus Platzgründen nicht eingegangen werden.
Sie geben nicht vor, wie die Operationen nun genau implementiert werden, auch die genaue Arbeitsweise der Methoden geben Sie nicht vor. Sie spezifizieren nur, auf welche Eingabe Ihre Software mit welcher Ausgabe reagieren soll. Man könnte hier auch von einem Black-Box-Prinzip sprechen.
Anschaulich kann man sich das Ganze wie eine Kapsel vorstellen, die eine undurchsichtige Hülle hat. Innerhalb dieser Kapsel befinden sich jetzt die Daten und die Algorithmen, mit denen die einzelnen Operationen arbeiten. Daten sind zum Beispiel Zähler und Nenner des Bruchs, vielleicht auch noch ein paar weitere Hilfsdaten, die für die Operationen benötigt werden. Algorithmen sind die Rechenvorschriften, mit denen die Operationen realisiert werden, wenn beispielsweise zwei Brüche addiert werden sollen.
Modell einer Datenkapsel
Autor: Ulrich Helmich 2019, Lizenz: siehe Seitenende.
Von außen kann man nicht auf die Daten und Algorithmen zugreifen, man sieht sozusagen nichts - wie bei einer Black Box.
Mit so einer Datenkapsel kann man natürlich nichts anfangen. Man muss "Löcher" in die Wand der Kapsel machen. Das init()-Loch in der Datenkapsel erlaubt es beispielsweise, einen Zähler und einen Nenner anzugeben, um einen neuen Bruch zu erzeugen. Aus dem getValue()-Loch kommt der Wert des Bruches heraus. Ein drittes Loch ist für die add()-Operation notwendig. Hier kann zunächst ein weiterer Bruch hineingesteckt werden, nach Ausführung der add()-Operation ändert sich dann der Wert des Bruches in der Datenkapsel, was Sie aber von außen nicht sehen können. Erst wenn Sie in das getValue()-Loch hineinsehen, merken Sie, dass sich der Wert des Bruchs geändert hat.
Technisch erreichen Sie eine Datenkapselung in Java, indem Sie die Attribute einer Klasse als private deklarieren. Diese Attribute sind dann von außen nicht mehr sichtbar. Das heißt, andere Klassen können diese Attribute nicht sehen, weder Lese- noch Schreiboperationen sind auf diese Attribute dann möglich. Nur die Methoden der eigenen Klasse können diese private-Attribute sehen und verändern. Diese Attribute sind im Innern der Datenkapsel versteckt.
Die Löcher in der Datenkapsel realisieren Sie in Java mit Hilfe von Methoden, die als public deklariert werden müssen. Die Parameter dieser Methoden geben dann an, was Sie in diese Löcher hineinstecken können. Die init()-Methode einer Klasse Bruch könnte beispielsweise so aussehen:
public void init(int z, int n)
{
zaehler = z;
nenner = n;
}
Die Attribute zaehler und nenner sind als private deklariert worden und daher von außen nicht sichtbar. Die Parameter z und n nehmen die Werte von außen in Empfang und übergeben die Werte dann an die Attribute zaehler und nenner.
Beispiel für Fortgeschrittene
Ein zweites Beispiel soll die Vorzüge der Datenkapselung demonstrieren. Wenn Sie dieses Beispiel verstehen wollen, müssen Sie sich allerdings bereits mit Arrays, Zeigertypen und dem Prinzip der Vererbung auseinandergesetzt haben.
Eine Stackmaschine ist ein Stack, der rechnen kann. Die Klasse Stackmaschine ist eine Tochterklasse der Klasse Stack, erbt also alle Attribute und Methoden der Klasse Stack. Betrachten wir nun die Implementation der add-Methode der Klasse Stackmaschine:
public void add()
{
double ergebnis = top();
pop();
ergebnis += top();
pop();
push(ergebnis);
}
In der Klasse Stack wurde der eigentliche Datenspeicher mit Hilfe eines Arrays von double-Zahlen implementiert. Theoretisch könnte die add-Methode also direkt auf das oberste und zweit oberste Arrayelement zugreifen; der Quelltext der add-Methode würde sich dann verändern:
public void add()
{
if (tos >= 1)
{
double ergebnis = liste[tos] + liste[tos-1]
tos--;
liste[tos] = ergebnis;
}
}
Ein solches Vorgehen würde aber zwingend voraussetzen, dass die Klasse Stack den Datenspeicher auf jeden Fall mit Hilfe eines Arrays implementiert hat. Was wäre aber, wenn der Stack mit Hilfe von Zeigertypen oder auf eine andere Weise realisiert wurde? Dann hätte der Programmierer, der add() auf diese Weise programmieren wollte, eben Pech gehabt.
Ein solches Pech kann man vermeiden, indem man ausschließlich die "offiziell zugelassenen" Methoden einer Klasse benutzt. Bei der Klasse Stack sind die Methoden top(), push() und pop() offiziell zugelassen, außerdem empty().
Um noch einmal auf das Bild der Datenkapsel zurückzukommen: Diese Methoden sind quasi die "Löcher" in der Datenkapsel.
Die Methode top() liefert immer den Wert des zuletzt hinzugefügten Stackelements, egal, ob der Stack mit Hilfe eines Arrays oder mit Hilfe einer linearen dynamischen Liste realisiert wurde. Die Methode funktioniert auf jeden Fall. Und pop() entfernt immer das zuletzt hinzugefügte Stackelement, egal, ob es ein Arrayelement mit dem Index 0 ist oder das erste Element einer dynamischen Liste.
Der erste Quelltext hält sich streng an das Prinzip der Datenkapselung. Es wird nur auf die "offiziellen" Schnittstellen-Methoden der Klasse Stack zugegriffen. Ein direkter Zugriff auf interne Datenstrukturen der Klasse Stack findet dagegen nicht statt. Das ist beim zweiten Quelltext aber der Fall; hier wird das Prinzip der Datenkapselung nicht berücksichtigt, und das kann schnell zu Vehlern vyhren.