Ein Parser in Pascal
Während meines Informatik-Studiums an der Universität Bielefeld Anfang der 90er Jahre hatte ich bei Prof. Dr. Rehmann einen Kurs über Compilerbau belegt, der speziell für den Informatik-Unterricht an NRW-Gymnasien zugeschnitten war. Im Unterricht habe ich dann die Inhalte dieses Kurses schülergerecht angewandt. Seit einigen Jahren gibt es jedoch einen neuen Kernlehrplan für das Fach Informatik, in dem zwar endliche Automaten und kontextfreie Grammatiken eine wichtige Rolle spielen, das Thema "Compilerbau" jedoch nicht mehr vorkommt.
Für interessierte Schüler (m/w/d) habe ich dennoch mal eine alte Pascal-Unit "ausgegraben", die einen Minicompiler implementiert. Wer Lust hat, kann sich ja mit dem Quelltext vertraut machen oder sogar versuchen, ihn unter Java zum Laufen zu bringen, was natürlich entsetzlich viele Punkte für die Quartalsnote geben würde, wenn das gelänge...
Ich werde den kompletten Quelltext der Unit besprechen. Fangen wir mit dem ersten Teil an.
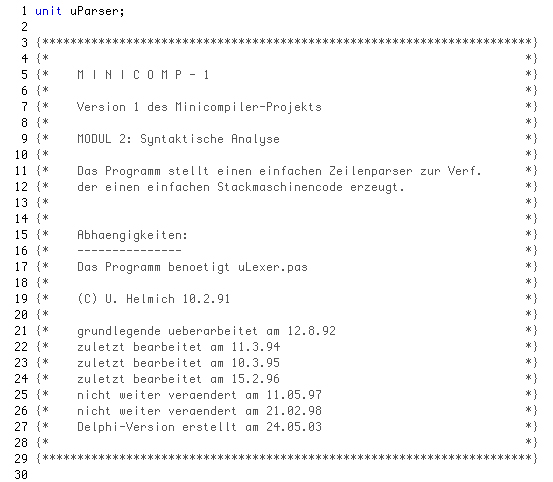
Dies ist der erste Abschnitt der Unit uParser. Es handelt sich um den Kopf der Unit mit einem einleitenden Kommentar. Man kann hier sehen, dass ich mich bereits seit 1991 mit dem Thema "Compilerbau" beschäftigt habe. Kein Wunder, das Thema war ja auch einer der Schwerpunkte in meinem Informatik-Studium an der Uni Bielefeld.

Der erste Teil einer Pascal-Unit beginnt immer mit dem Schlüsselwort interface. Alles was in diesem interface-Teil steht, ist öffentlich oder public, wie man in Java sagen würde.
Als nächstes sehen wir in den Zeilen 34 - 54 (in Pascal / Delphi gibt es keine Zeilennummern, die habe ich nur der besseren Orientierung wegen mit abgedruckt) die Definition der Klasse TParser. In Java würden wir die Klasse einfach Parser nennen.
Genau wie in Java unterscheidet man auch in Delphi zwischen öffentlichen (public) und nichtöffentlichen (private) Attributen und Methoden. Und genau wie eine Java-Klasse hat auch eine Delphi-Klasse einen Konstruktor, der allerdings einen beliebigen Namen wie z.B. "Init" haben darf.
Die Methoden Match(), Term, Factor und Expr sowie Parse sind öffentlich, während alle Attribute sowie die Methoden WriteCode() und WriteError() privat sind.
Während bei einer Java-Methode an Ort und Stelle hingeschrieben wird, wie die Methode arbeitet, unterscheidet man in Delphi zwischen der Deklaration und der Implementation einer Methode. Im Interface-Teil sehen wir nur die Deklaration der Klasse TParser. Die Implementation folgt in einem eigenen Implementations-Teil.

Hier sehen wir den Beginn dieses Implementations-Teils. Er fängt an mit dem Schlüsselwort implementation, dann kommen die Aufrufe anderer Units. Dies ist in etwa vergleichbar mit dem import-Befehl in Java.
Als erstes wird der Konstruktor der Klasse TParser implementiert. Der Konstruktor erhält als Parameter erstens die Zeile, die er analysieren soll, z.B.
"Umfang = 2 * Pi * Radius;"
Der zweite Parameter fn ist der Name (filename) der Textdatei, in der er den erzeugten Stackmaschinencode speichern soll. Der dritte Parameter schließlich ist ein graphisches Delphi-Element, in dem kurze Notizen angezeigt werden können; auf das wir hier aber nicht weiter eingehen müssen. In Java würde man dazu ein Editfield oder Ähnliches nehmen.
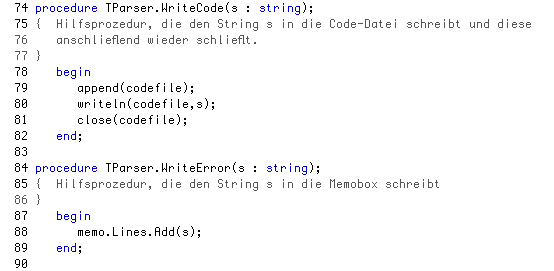
Und weiter geht es mit den Zeilen 74 bis 89, die die Implementation der beiden privaten Methoden WriteCode() und WriteError() beinhalten. In der Zeile 79 wird die Textdatei zum Schreiben geöffnet, und der Zeile 80 wird dann der String s an die letzte Zeile der Datei angehängt, und in Zeile 81 wird die Textdatei wieder geschlossen, so dass andere Programme darauf zugreifen können.
In der Zeile 88 wird der String s an den Text angehängt, der bereits in der MemoBox zu sehen ist.

Hier sehen wir die mysteriöse Methode Match(), deren Bedeutung ich immer noch nicht so ganz richtig verstanden habe. Laut Literatur soll Match() erstens überprüfen, ob das übergebene Token t mit dem aktuellen Tokentyp look.tokentype übereinstimmt, und zweitens das nächste Token vom Lexer abholen. Jede Änderung dieser Prozedur Match() meinerseits hat stets zu unerfreulichen Ergebnissen geführt, daher lasse ich diese Prozedur seit ca. 1992 unverändert bestehen. Sie funktioniert, aber warum sie eigentlich funktioniert, habe ich immer noch nicht so recht verstanden.
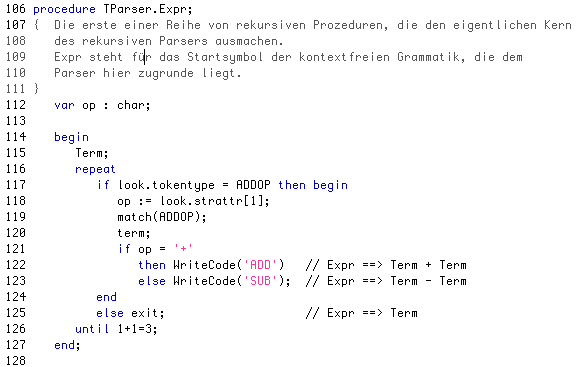
Diese Methode ist nach den Regeln 1 und 2 der Parserkonstruktion geschrieben wurden. Allerdings wurde die Methode dann wieder vereinfacht, verbessert und noch zwei- oder dreimal verändert. Sie arbeitet in dieser Form jedenfalls mehr oder weniger fehlerfrei.
Vergleichen wir noch einmal mit den entsprechenden Produktionen unserer letzten Grammatik:
P1 Expr ---> Term Moreterms P2 Moreterms ---> + Term [print "add"] Moreterms P3 Moreterms ---> - Term [print "sub"] Moreterms P4 Moreterms ---> nothing
Nach Regel 1 - angewandt auf Produktion 1 - muss die Methode Expr als erstes die Methode Term aufrufen. Das ist hier auch tatsächlich der Fall. Dann müsste als zweites die Methode Moreterms aufgerufen werden. Das wurde in den Zeilen 116ff anders geregelt. Und zwar wurde der Quelltext der Methode Moreterms direkt in den Quelltext der Methode Expr integriert. Das erste Symbol auf der rechten Seite der Produktion 2 bzw. 3 ist ein Additionsoperator, entweder Plus oder Minus. Daher erfolgt nach Regel 1 der Aufruf der Match-Methode; allerdings wird vorher kontrolliert, ob das lookahead tatsächlich ein Additionsoperator ist. Sowohl bei Produktion 2 wie auch bei Produktion 3 kommt dann der Aufruf von Term. Dies ist nach Regel 1 auch bei der Prozedur TParser.Expr realisiert worden. Schließlich kommt die Phase der Codeerzeugung. Jetzt muss die Methode nachschauen, welches Stringattribut das Token hat und dann entweder "add" oder "sub" schreiben.
Die Sache mit der Endlosschleife
repeat … until 1+1 = 3;
ist auch so ein Ding! Ich könnte jetzt nicht erkären, wieso hier eine Endlosschleife eingebaut werden muss. Lässt man sie jedoch weg, funktioniert die ganze Methode nicht mehr fehlerfrei. So ist das halt beim Programmieren, es ist immer eine Mischung aus angewandter Theorie und praktischer Notwendigkeit. Durch Herumexperimentieren kommt man oft weiter als durch stures Einhalten von Regeln. Aber nicht immer, und das ist das Schlimme.
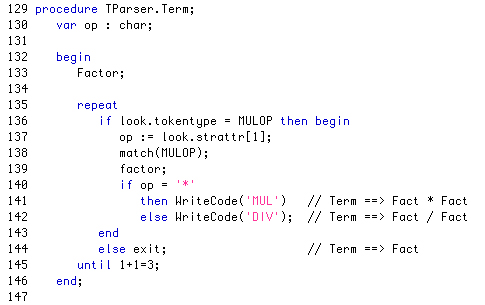
Diese Methode ist nach dem gleichen Strickmuster gebaut wie die Methode Expr, daher muss ich hier ja wohl nicht mehr viel zu schreiben.
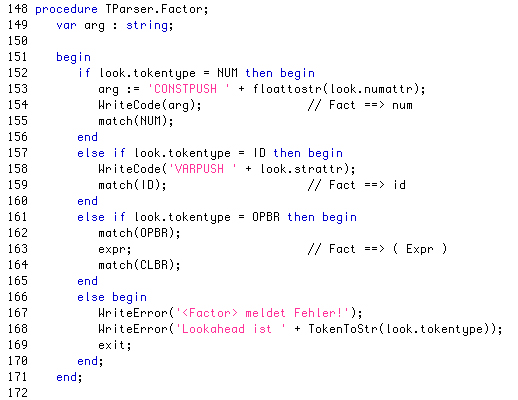
Hier kommt mehr oder weniger die Regel 2 zur Anwendung. Allerdings wird nicht immer mit der ganzen First-Menge verglichen, sondern es werden ganz konkrete Fälle unterschieden. Wenn es sich bei dem aktuellen Token um eine Zahl (num) handelt, wird "Constpush" in die Datei geschrieben, anschließend wird das nächste Token vom Lexer abgeholt. Handelt es sich beim lookahead um einen Bezeichner, so wird entsprechend "Varpush" mit dem Variablennamen in die Codedatei geschrieben und das nächste Token geholt. Erkennt die Prozedur Factor dagegen eine offene Klammer, so "weiß" die Prozedur, dass jetzt die Produktionsregel
Factor --> (Expr)
"dran" ist, was dann gemäß Regel 1 umgesetzt wird. In allen anderen Fällen wird einfach eine Fehlermeldung ausgegeben.

Dies sind die letzten Zeilen der Unit uParser. Wir sehen noch die Methode Parse, welche sozusagen die Hauptmethode der Klasse TParser ist. Es wird zunächst das erste Token vom Lexer geholt und dann die Methode Expr aufgerufen.