Probleme bei der Implementierung eines Lexers
Die Klasse Lexer, die Sie auf der letzten Seite gesehen haben, stellt Methoden zur Verfügung, die analysieren, ob ein übergebener String eine double-Zahl oder eine int-Zahl ist. Java-Bezeichner würde der Lexer auf ähnliche Weise erkennen.
Das alles ist ja ganz nett, für die praktische Implementation eines Lexers reicht das aber noch lange nicht aus. Bei einem "echten" Lexer geht es nämlich nicht darum, zu beurteilen, ob der String "radius" ein Bezeichner und der String "3.14" eine double-Zahl ist, sondern es soll immer ein kompletter Java-Befehl analysiert werden, z.B. die Zuweisung
umfang = 2*pi * radius;
Hier tauchen ganz neue Probleme auf. Der String "umfang = 2*pi * radius" ist weder ein Bezeichner noch eine Zahl, sondern eine Zuweisung. Zur lexikalischen Analyse muss der Lexer diesen String erst in seine einzelnen Bestandteile zerlegen. Ein erster Schritt der Analyse wäre das Entfernen von Leerzeichen, die ja eigentlich nicht benötigt werden, sondern vom Programmierer nur aus Gründen der besseren Übersichtlichkeit hinzugefügt wurden. Nach Entfernung der Leerzeichen sieht der zu analysierende String so aus:
umfang=2*pi*radius;
An dieser Stelle können wir gleich die nächste praktische Übung einschieben, damit Ihnen vor lauter Theorie nicht die Gehirnzellen kollabieren.
Übung 25-5.1
Schreiben Sie für die Klasse Lexer eine Methode, die sämtliche Leerzeichen aus einem gegebenem String entfernt.
Zurück zu den Problemen bei der Implementierung eines Lexers. Schauen wir uns noch einmal den DEA zur Erkennung von Bezeichnern an:
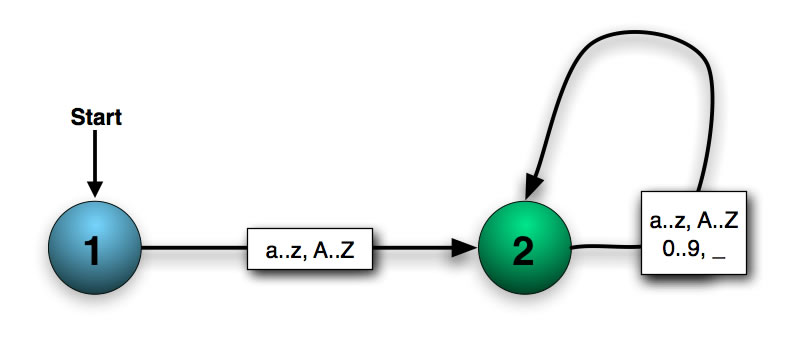
Darstellung eines Java-Bezeichners durch einen determinierten endlichen Automaten mit zwei Zuständen
und betrachten wir dann noch einmal die Quelltextzeile
umfang=2*pi*radius;
die unser Lexer analysieren soll. Der Lexer bzw. der "eingebaute" DEA des Lexers erkennt das Zeichen 'u', wodurch der DEA vom Startzustand 1 und den Endzustand 2 gelangt. Nun kommen weitere Zeichen wie 'm', 'f' und so weiter, hier bleibt der DEA im Zustand 2. Nach dem Zeichen 'g' kommt das Zeichen '='. Damit kann der "DEA für Bezeichner" aber nichts mehr anfangen, das Zeichen '=' ist nicht im Alphabet dieses Automaten enthalten. Trotzdem darf der Lexer jetzt keinen Fehler melden, denn laut Java-Syntax darf ja nach einem Bezeichner ein Operator oder ein Zuweisungssymbol kommen.
Wir brechen die Folge 25 an dieser Stelle einmal ab. In den vorherigen Versionen habe ich von meinen Schülern immer einen kompletten Lexer "basteln" lassen, der durchaus in der Lage war, komplette Zuweisungen wie die obige in ihre Einzelbestandteile (Token) zu zerlegen. Aber wenn man einmal im Kernlehrplan NRW nachschaut, ist das ganze Thema überhaupt nicht abiturrelevant. Leistungsstarke Schüler, die hiermit unterfordert sind, können sich ja gern meinen alten Delphi-Quelltext anschauen, der einen vollständigen Lexer modelliert, und versuchen, ihn nach Java zu übersetzen. Viel Spaß dabei; helfen kann ich Ihnen aber nicht mehr dabei, da ich seit über 10 Jahren nicht mehr in Delphi programmiert habe.
Allerdings gibt es ein abiturrelevantes Thema, das im Zusammenhang mit endlichen Automaten steht, nämlich das Thema "reguläre Sprachen" und - eher für den Informatik Leistungskurs gedacht - "nichtdeterminierte endliche Automaten".
Weiter mit 25.6 Reguläre Sprachen...