Sinn und Zweck
Speichern von Schlüssel-Wert-Paaren
Eine HashMap ist eine Datenstruktur zum Speichern von Schlüssel-Wert-Paaren, also beispielsweise Name → Telefonnummer, Name → Adresse, Kundennummer → Kunde oder Artikelnummer → Artikel.
Jedem Schlüssel ist dabei genau ein Wert zugeordnet. Über den Schlüssel kann der zugehörige Wert sehr schnell wiedergefunden werden.
Warum speichert man solche Schlüssel-Wert-Paare nicht einfach in einer ArrayList oder in einem Array?
Der Grund liegt in der Zugriffszeit. In einer Liste oder in einem Array muss ein bestimmtes Element in der Regel erst gesucht werden. Selbst bei günstigen Verfahren wie der binären Suche ist dazu eine sortierte Datenstruktur erforderlich. Die HashMap geht einen anderen Weg: Aus dem Schlüssel wird direkt berechnet, in welchem Bereich der internen Datenstruktur der Eintrag zu finden ist.
Dazu verwendet die HashMap eine Hash-Funktion. Sie erzeugt aus dem Schlüssel einen ganzzahligen Hash-Wert. Aus diesem Hash-Wert wird anschließend der Index des zugehörigen Buckets berechnet.
Sucht man später nach einem bestimmten Wert, so wird aus dem Schlüssel erneut ein Hash-Wert und daraus der passende Bucket-Index berechnet. Dadurch ist kein Durchlaufen einer ganzen Liste mehr nötig; der Zugriff erfolgt im Durchschnitt in konstanter Zeit.
Während das Suchen in einer unsortierten Liste meist eine Laufzeit von O(n) hat, ermöglicht eine HashMap das Einfügen und Finden von Einträgen im Durchschnitt in O(1). Gerade bei großen Datenmengen ist das ein großer Vorteil.
Interne Implementierung
Eine HashMap verwendet intern vor allem ein Array, dessen Elemente als Buckets bezeichnet werden. In diesen Buckets liegen die eigentlichen Einträge der Map. Kommt es zu Kollisionen, so können in einem Bucket mehrere Einträge gespeichert sein.
Betrachten wir dazu ein konkretes Beispiel. In einer HashMap sollen die Noten von zehn Schülern und Schülerinnen gespeichert werden, jeweils mit einer Liste von Fachnoten als Wert. Auf die Einzelheiten des Programms soll hier nicht eingegangen werden; interessant ist vor allem der Blick in den BlueJ-Objektinspektor.
Betrachten wir nun die erzeugte HashMap mit dem BlueJ-Objektinspektor.
Die Instanzvariablen einer HashMap
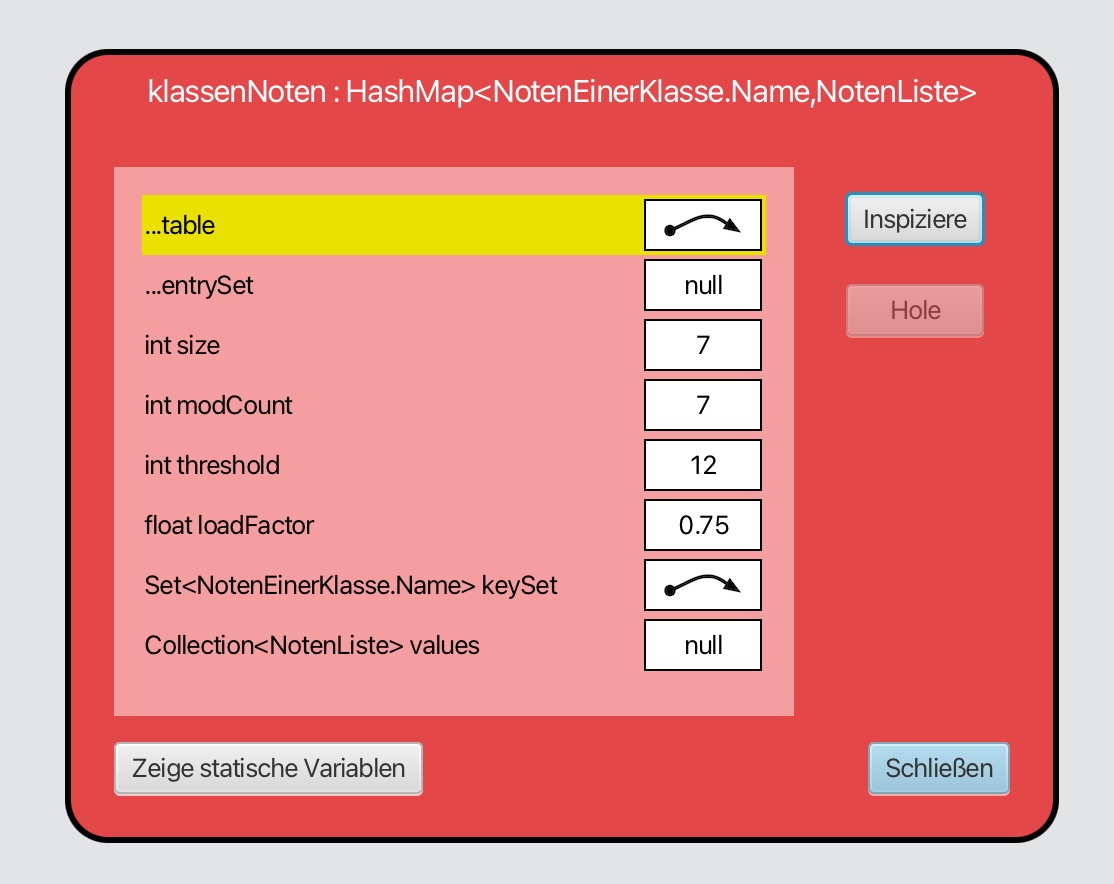
Die HashMap klassenNoten im BlueJ-Objektinspektor
Dieses Bild zeigt mehrere Instanzvariablen des HashMap-Objekts klassenNoten.
Gehen wir diese Variablen der Reihe nach durch.
table
- Diese Instanzvariable verweist auf das zentrale Array der HashMap. Jedes Element dieses Arrays ist ein Bucket, also ein Platz, an dem Einträge mit passendem Index abgelegt werden.
entrySet
- Eine Sicht auf alle Schlüssel-Wert-Paare der Map. Sie wird bei Bedarf erzeugt und dann zwischengespeichert.
size
- Die aktuelle Anzahl der in der HashMap gespeicherten Schlüssel-Wert-Paare.
modCount
- Die Anzahl der strukturellen Änderungen, denen die HashMap unterzogen wurde. Jedes Einfügen oder Entfernen eines Eintrags erhöht diesen Wert.
threshold
- Ab diesem Grenzwert wird die interne Tabelle vergrößert. Wird der Wert von size zu groß, so wird die Kapazität der HashMap erhöht und die Einträge werden neu verteilt.
loadFactor
- Mit diesem Wert wird festgelegt, wie stark die HashMap im Mittel gefüllt sein darf, bevor sie erweitert wird. Der Standardwert ist 0,75.
- loadFactor ist also ein Verhältnis, threshold dagegen die konkrete Eintragszahl, ab der eine Vergrößerung erfolgt.
keySet
- Eine Sicht auf alle aktuell gespeicherten Schlüssel. Auch sie wird erst bei Bedarf erzeugt.
values
- Eine Sicht auf alle aktuell gespeicherten Werte der Map. Auch hier erfolgt die Erzeugung erst bei Bedarf.
Das Rückgrat der HashMap
Wenn wir im Objektinspektor auf den Pfeil der Instanzvariablen table doppelklicken, erhalten wir folgendes Bild:
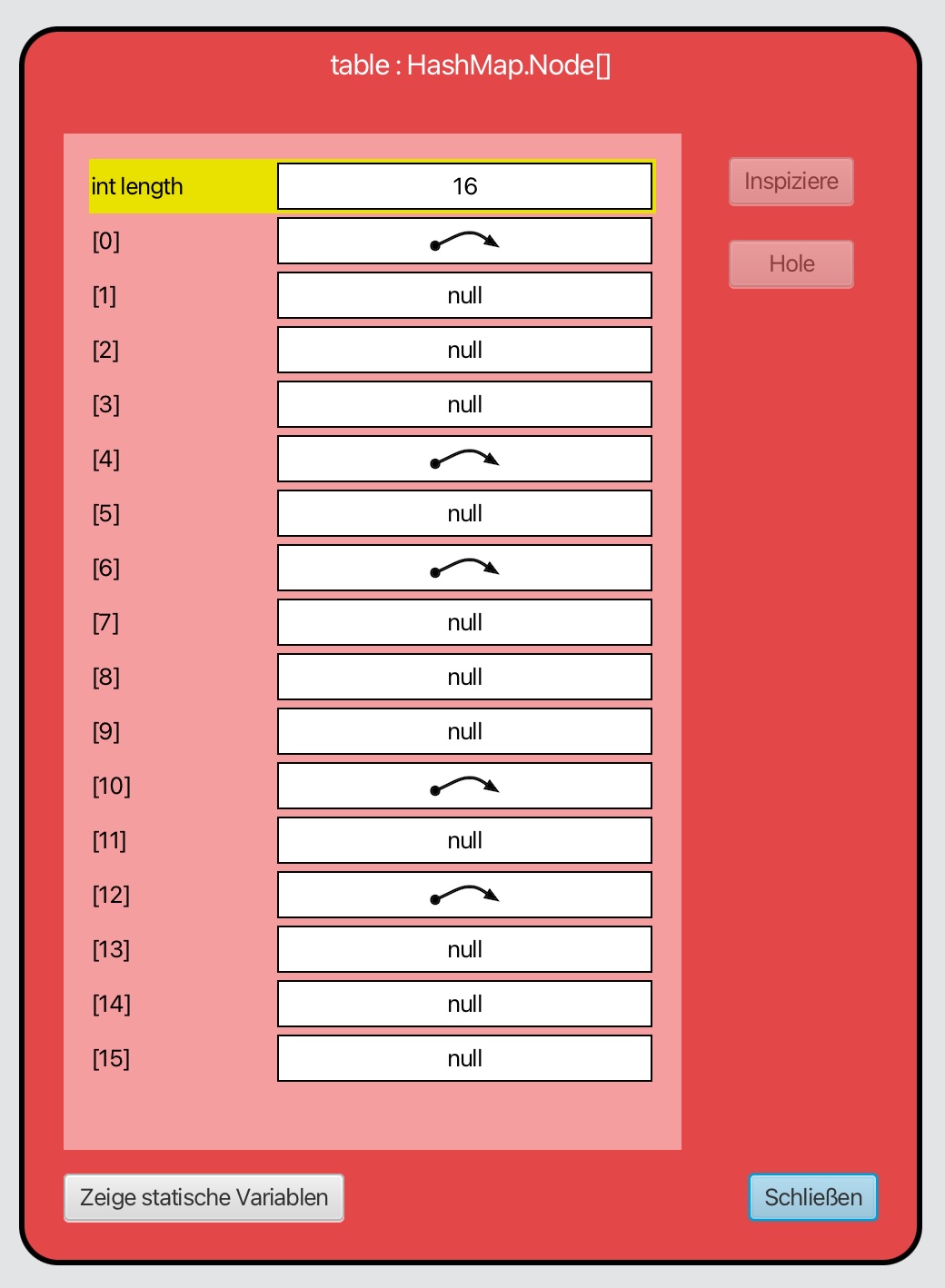
Der Bucket-Array einer HashMap
Hier sehen wir ein Array mit 16 Buckets. Im Testprogramm wurden sieben Schlüssel-Wert-Paare in die HashMap eingefügt. Dennoch zeigen in diesem Bild nur fünf Buckets eine Referenz auf einen Eintrag. Offensichtlich befinden sich also mehrere Einträge in denselben Buckets.
Die Buckets der HashMap
Wir doppelklicken nun auf den ersten Pfeil:
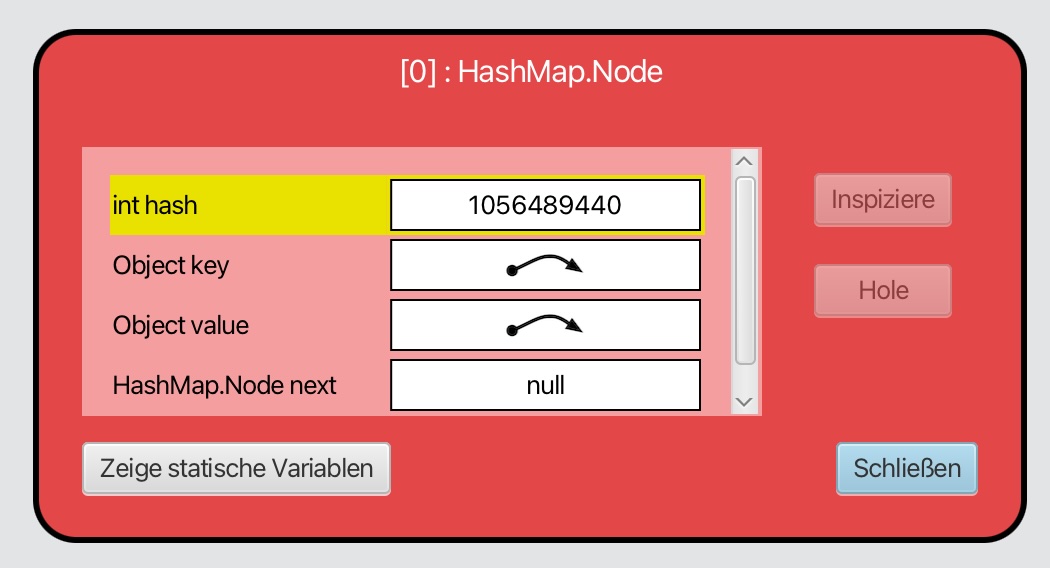
Der Inhalt des ersten Buckets
Die erste Instanzvariable dieses Knotens ist der Hash-Wert. Dieser wird aus dem Schlüssel berechnet, in unserem Beispiel also aus einem Datensatz, der den Nachnamen und den Vornamen einer Person enthält.
Die Instanzvariable key verweist auf den Schlüssel, die Instanzvariable value auf den zugehörigen Wert, hier also auf die Notenliste.
Die Instanzvariable next hat hier den Wert null. Das bedeutet: In diesem Bucket befindet sich kein weiterer Eintrag.
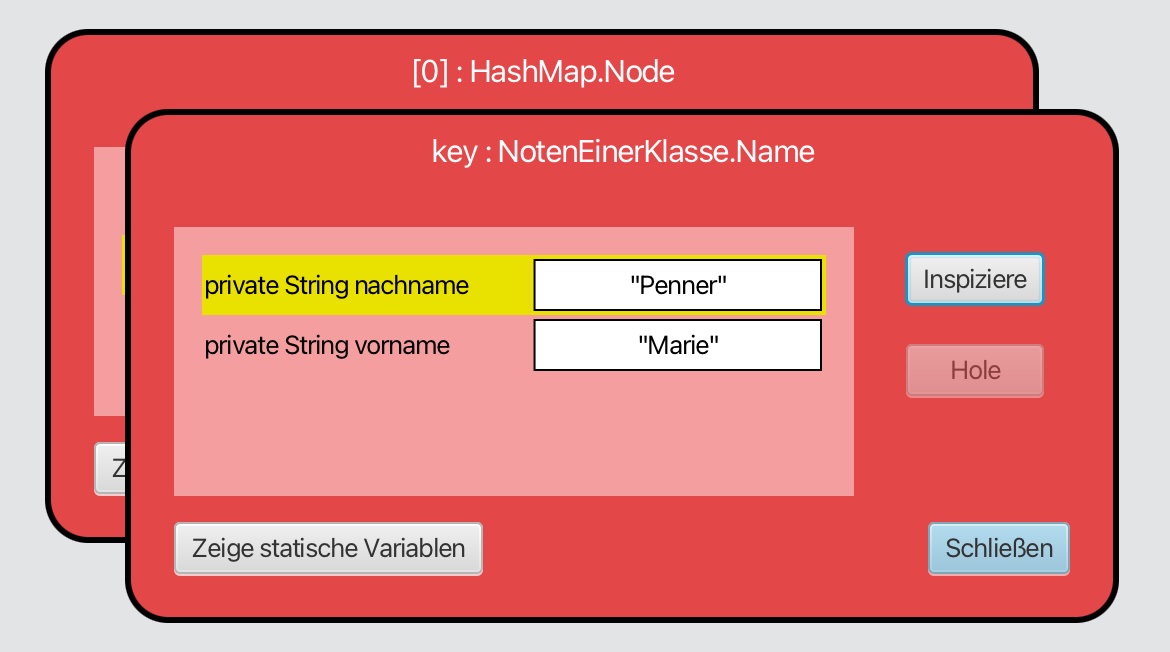
Die Referenzvariable key zeigt auf einen Record aus Nachname und Vorname
Wenn wir auf den Pfeil bei key doppelklicken, öffnet sich der Schlüssel im Objektinspektor. Hier ist gut zu erkennen, dass der Schlüssel aus zwei Strings besteht: dem Nachnamen und dem Vornamen.
Wir doppelklicken nun auf ein weiteres Element des Bucket-Arrays. Auch dort hat die Instanzvariable next den Wert null. Beim nächsten Eintrag wird es dann interessanter:
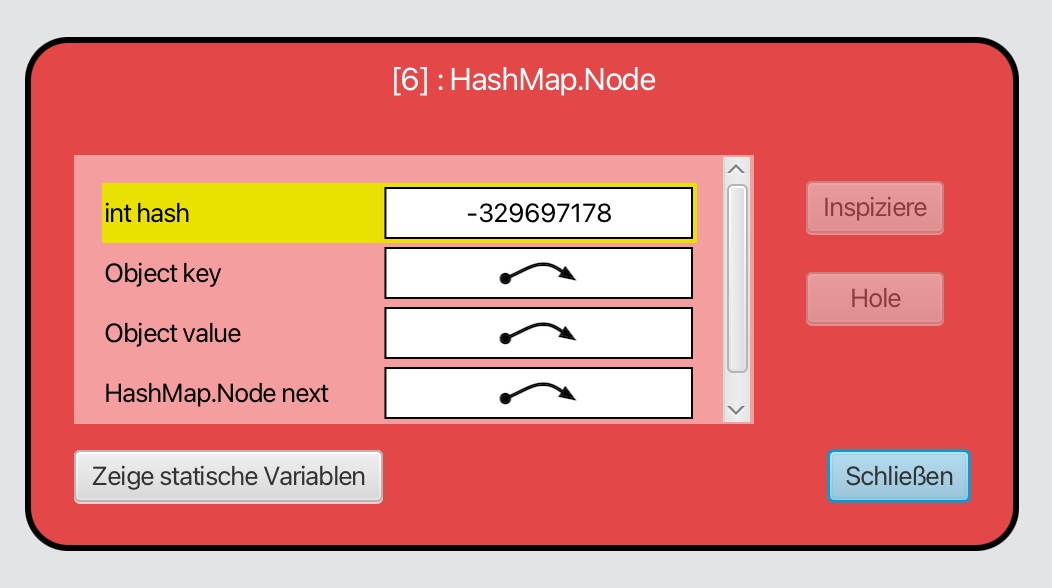
Ein Bucket mit Nachfolger
Hier taucht plötzlich ein Pfeil bei der Instanzvariablen next auf. Wenn wir auf diesen Pfeil doppelklicken, erhalten wir:
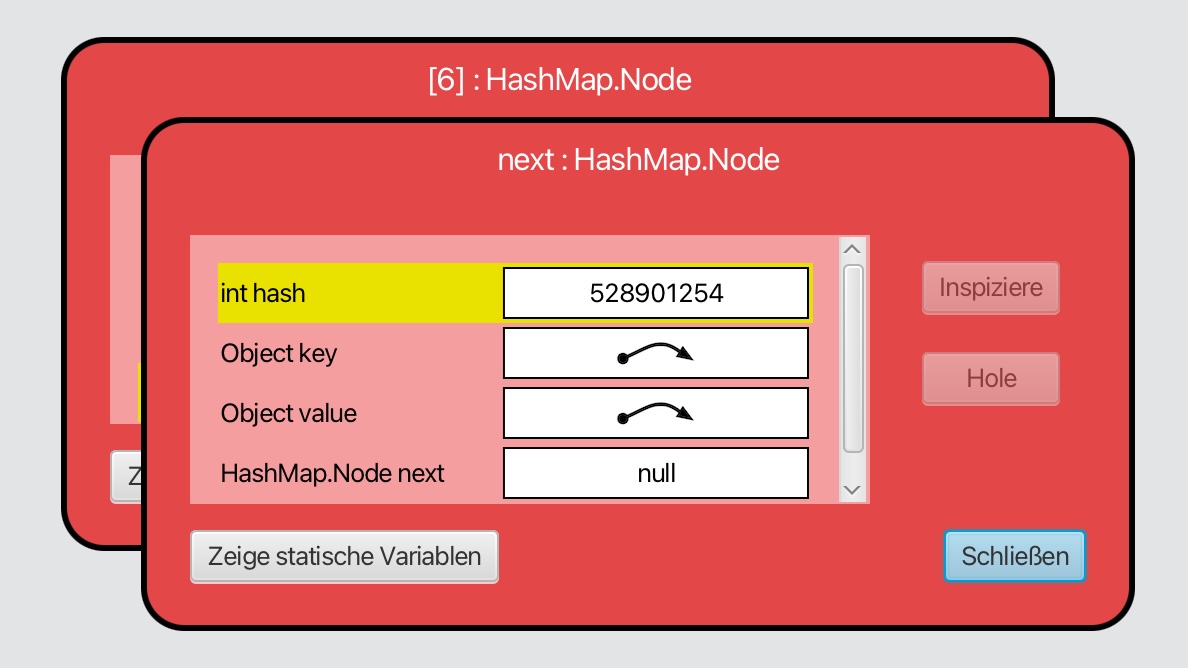
Der Nachfolger eines Bucket-Eintrags
Der Eintrag verweist also auf einen zweiten Eintrag, auf einen Nachfolger. Dessen Instanzvariable next hat wieder den Wert null; die Kette endet also dort.
Der Inhalt dieses Buckets besteht somit aus zwei Knoten, wobei der erste auf den zweiten verweist. Es handelt sich also um eine einfach verkettete lineare Liste.
Auf die gleiche Weise kann auch ein anderer Bucket mehrere Knoten enthalten. So erklärt sich, warum in der HashMap insgesamt sieben Einträge gespeichert sind, obwohl im Bucket-Array nur fünf Buckets belegt erscheinen. Das stimmt dann mit dem Wert von size überein.
Wann bekommt ein Eintrag einen eigenen Bucket, und wann wird er als Nachfolger an einen bereits belegten Bucket angehängt?
Kollisionsbehandlung
Es kann vorkommen, dass zwei verschiedene Schlüssel im selben Bucket landen. Das nennt man eine Kollision. Die Ursache kann darin liegen, dass zwei Schlüssel denselben Hash-Wert besitzen; es kann aber auch sein, dass unterschiedliche Hash-Werte nach der Index-Berechnung auf denselben Bucket führen.
In diesem Fall wird der neue Eintrag nicht in einem neuen Bucket gespeichert, sondern an die vorhandene Struktur dieses Buckets angehängt. Zunächst geschieht das in Form einer einfach verketteten Liste.
Wird ein Bucket zu stark überfüllt, kann die HashMap diese Liste intern in einen balancierten binären Suchbaum umwandeln. Dadurch verbessert sich die Suche in diesem Bucket deutlich: Statt einer linearen Laufzeit von O(n) ergibt sich dann im Idealfall eine logarithmische Laufzeit von O(log n).
Wichtig ist außerdem: Eine HashMap erkennt gleiche Schlüssel nicht nur anhand des Hash-Wertes, sondern prüft bei Bedarf auch mit equals(), ob zwei Schlüssel logisch gleich sind. Deshalb müssen bei selbst definierten Schlüsselklassen die Methoden equals() und hashCode() konsistent zueinander passen. Andernfalls kann es passieren, dass logisch gleiche Schlüssel von der HashMap nicht korrekt wiedergefunden werden.
Berechnung des Hash-Wertes bzw. des Index im Bucket-Array
1. Hash-Wert berechnen
Aus dem Schlüssel wird zunächst ein Hash-Wert berechnet. Jedes Java-Objekt besitzt dazu die Methode hashCode(). Die HashMap ruft diese Methode für den Schlüssel auf und erhält so eine ganze Zahl.
2. Hash-Spreading
Dieser Hash-Wert wird intern noch weiterverarbeitet, damit sich die Einträge möglichst gleichmäßig über die Buckets verteilen. Diese zusätzliche Verarbeitung nennt man Hash-Spreading.
3. Index-Berechnung
Aus dem so aufbereiteten Hash-Wert wird anschließend der Index im Bucket-Array table[] berechnet. Das geschieht mit folgender Anweisung:
int index = (n - 1) & hash;
Dabei ist n die aktuelle Länge des Arrays, also beispielsweise 16, 32 oder 64. Diese Länge ist immer eine Zweierpotenz.
Der Operator & arbeitet hier als Bitmaske. Bei einer Arraygröße von 16 hat n - 1 den Binärwert 0000 1111. Dadurch werden bei der Berechnung des Index nur die untersten vier Bits des Hash-Wertes berücksichtigt. Der resultierende Index liegt also zwischen 0 und 15.
Auch hier zeigt sich noch einmal: Verschiedene Hash-Werte können durchaus auf denselben Bucket-Index führen. Genau deshalb sind Kollisionen bei HashMaps grundsätzlich möglich.
Merke:
HashMap
-
Eine HashMap speichert Schlüssel-Wert-Paare, zum Beispiel Name → Telefonnummer.
-
Jeder Schlüssel kommt höchstens einmal vor und ist genau einem Wert zugeordnet.
-
Der Zugriff erfolgt über den Schlüssel, nicht über eine Position wie bei Arrays oder Listen.
-
Intern verwendet die HashMap ein Array von Buckets.
-
Aus dem Schlüssel wird mit hashCode() ein Hash-Wert berechnet; daraus wird der Bucket-Index abgeleitet.
-
Dadurch sind Einfügen und Suchen im Durchschnitt in O(1) möglich.
-
Kollisionen entstehen, wenn verschiedene Schlüssel im selben Bucket landen.
-
Solche Kollisionen werden intern zunächst durch Verkettung gelöst, bei vielen Einträgen in einem Bucket gegebenenfalls auch durch Baumstrukturen.
-
Für selbst definierte Schlüsselklassen müssen equals() und hashCode() konsistent implementiert sein.
-
Eine HashMap ist besonders geeignet, wenn große Mengen von Daten schnell über einen Schlüssel gefunden werden sollen.
Quellen:
- Lahres et al.: Objektorientierte Programmierung, Rheinwerk Computing 2021.
- Barnes, Kölling: Java lernen mit BlueJ - Objects first. Pearson-Verlag 2019.
- Ullenboom: Java ist auch eine Insel, Rheinwerk Computing 2023.
- Oracle Dokumentation zur Klasse HashMap.
- "A Guide to Java HashMap" auf www.baeldung.com
- "The Java HashMap Under the Hood" auf www.baeldung.com, 2023